Análisis de ingeniería sobre el mantenimiento de almacenes automatizados: sistemas de alta densidad, robótica móvil, control industrial y los indicadores que sostienen tu disponibilidad.
Gestión de riesgos en sistemas de almacenamiento cúbico
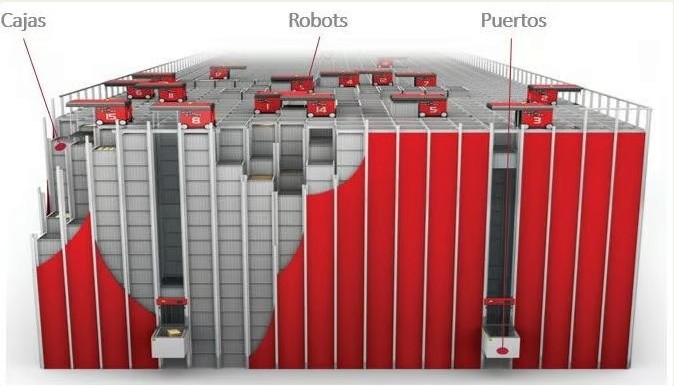
Los sistemas de almacenamiento en cubo pertenecen a la familia de los ASRS (Automated Storage and Retrieval Systems, sistemas automatizados de almacenamiento y recuperación). A diferencia de un almacén convencional, la mercancía no se guarda en estanterías recorridas por pasillos: se entierra bajo una rejilla por la que circula una flota de robots operando en enjambre. Esa arquitectura es la que dispara la densidad —y la que concentra el riesgo en cada metro cuadrado de grid.
El enjambre: por qué un solo robot bloqueado escala
La eficiencia del Cube Storage (arquitectura popularizada por AutoStore y sistemas equivalentes) se basa en que decenas de robots comparten una misma malla superior, accediendo a las cubetas mediante un movimiento vertical de extracción. No hay redundancia espacial: donde en un almacén convencional un pasillo bloqueado se rodea, aquí un robot detenido sobre la rejilla puede inutilizar un sector completo del grid y forzar el redireccionamiento de tráfico del resto de la flota.
El impacto no es lineal. Un robot inmovilizado sobre una celda crítica —por ejemplo, sobre uno de los pocos puertos de presentación (ports)— degrada el throughput de toda la instalación, no solo el suyo. En picos de actividad, donde el sistema trabaja cerca del 100% de su capacidad de presentaciones por hora, esa degradación se traduce de inmediato en pedidos que no salen dentro de la ventana de transporte.
Incidencia en grid · simulaciónSECTOR B-04 · TRÁFICO REENRUTADO
Una cubeta deformada o desalineada (celda en rojo) bloquea físicamente el paso sobre la rejilla. El controlador de tráfico detiene los robots adyacentes y reenruta el resto de la flota: la incidencia de una sola celda se propaga en efecto dominó y reduce la disponibilidad agregada de todo el almacén.
Robot operativo Cubeta bloqueada Zona detenida / reenrutada
Calibración de sensores ópticos y desgaste de ruedas
Los dos modos de fallo recurrentes en la flota tienen origen mecánico y optomecánico, y ambos son prevenibles:
Ruedas y rodillos de tracción y de elevación. El robot alterna desplazamiento sobre los dos ejes de la rejilla y elevación de cubetas. El desgaste asimétrico de ruedas provoca pérdida de precisión de posicionamiento, vibración y, en última instancia, fallos de lectura de celda. Un programa preventivo mide el perfil de desgaste y sustituye por condición, no por avería.
Sensores ópticos y de posición. La navegación sobre el grid depende de la lectura fiable de las marcas de referencia. Polvo, microdesalineación o degradación del emisor desplazan la calibración fuera de tolerancia. Un sensor que aún "funciona" pero lee con margen reducido es el preludio típico de un bloqueo en plena campaña.
La calibración no es una tarea de emergencia: es una rutina con frecuencia definida que debe ejecutarse dentro de una ventana de mantenimiento preventivo planificada, no improvisada cuando el robot ya ha caído.
Sistema de almacenamiento en cubo (tipo AutoStore): robots en enjambre sobre la rejilla, cubetas y puertos.
La ventana de mantenimiento como activo, no como interrupción
El error de gestión más común es percibir la ventana preventiva como tiempo de producción perdido. En un sistema de enjambre es justo lo contrario: la ventana planificada es lo que evita la parada no planificada, que siempre llega en el peor momento y con un MTTR muy superior. Intervenir un robot dentro de una ventana programada cuesta minutos de una unidad; intervenirlo en caliente, durante el pico, cuesta capacidad de toda la flota.
Una política preventiva madura segmenta la flota y rota las intervenciones para que el sistema nunca pierda más de un porcentaje acotado de robots simultáneamente, preservando el throughput agregado mientras se mantiene cada unidad.
Asegurar el cumplimiento del SLA contratado
Cuando un sistema de cubos opera bajo un SLA de disponibilidad, conviene recordar la aritmética: un compromiso del 99% de disponibilidad equivale a unas 87,6 horas de parada permitida al año —pero esas horas no se reparten de forma uniforme. Si se concentran en la peak season, el SLA se cumple sobre el papel y se incumple en la operación real.
Por eso el cumplimiento de SLA en Cube Storage se gestiona con tres palancas medibles: elevar el MTBF de cada robot mediante sustitución por condición, reducir el MTTR con repuestos críticos en stock y procedimientos documentados, y desplazar las intervenciones fuera de las ventanas de máxima demanda. Sin datos de estos tres indicadores, el SLA es una promesa; con ellos, es un riesgo gestionado.
Conclusión operativa: en alta densidad, la tolerancia al fallo es baja por diseño. El mantenimiento preventivo de la flota —calibración óptica, control de desgaste y rotación planificada— no es un coste de servicio: es la condición para que la densidad que justificó la inversión siga siendo rentable.
De los AGV tradicionales a la flexibilidad de los AMR
AGV y AMR comparten misión —mover material sin conductor— pero no comparten arquitectura. Tratarlos como la misma máquina en el plan de mantenimiento es una de las causas más frecuentes de downtime evitable en plantas que conviven con flotas mixtas.
Conviene fijar primero los términos: los AGV son los Automated Guided Vehicles (vehículos de guiado automático) y los AMR los Autonomous Mobile Robots (robots móviles autónomos). La diferencia no es de marca ni de generación comercial, sino de principio de funcionamiento —y ese principio determina cómo se mantiene cada flota.
Guiado fijo frente a navegación natural
El AGV (Automated Guided Vehicle) sigue una infraestructura física: banda magnética, hilo embebido, marcas ópticas o reflectores láser triangulados. Es determinista y robusto, pero rígido: cualquier cambio de ruta exige modificar la infraestructura. El AMR (Autonomous Mobile Robot) prescinde de esa guía y practica navegación natural: construye y consulta un mapa del entorno en tiempo real, localizándose por SLAM (Simultaneous Localization and Mapping) a partir de la fusión de sensores.
Esta diferencia conceptual cambia por completo el diagnóstico. En un AGV, un fallo de trayectoria suele rastrearse a la infraestructura de guía o al sensor que la lee. En un AMR, el mismo síntoma —el robot "se pierde"— puede originarse en el LiDAR, en la odometría, en la calidad del mapa o en la fusión de sensores. El especialista no sustituye: aísla en qué capa de la pila de navegación está el problema.
Sensórica LiDAR: el componente que define la disponibilidad del AMR
El LiDAR es, a la vez, el sensor de seguridad y el de localización del AMR. Su mantenimiento no admite improvisación:
Limpieza y estado óptico. Una óptica con polvo o arañazos degrada el alcance y la nube de puntos; el robot reduce velocidad por seguridad —pérdida silenciosa de productividad— antes de fallar abiertamente.
Verificación funcional de seguridad. En LiDAR de seguridad certificados, los campos de protección deben verificarse periódicamente; es mantenimiento con implicación normativa, no solo operativa.
Calidad del mapa. Un entorno que cambia (racks reconfigurados, estacionalidad) degrada la localización. El "mantenimiento" del AMR incluye mantener vivo y vigente su mapa, algo que no existe en el mundo AGV.
En el AMR, el LiDAR es a la vez sensor de seguridad y de localización: su estado define la disponibilidad.
Desgastes mecánicos diferenciados
La libertad de trayectoria del AMR tiene un coste mecánico. Al no circular siempre por la misma línea y al ejecutar giros y reorientaciones continuas, el patrón de desgaste de ruedas motrices, ruedas locas y reductoras difiere del AGV, que repite trayectoria y desgasta de forma más predecible. El plan preventivo debe reflejar esa diferencia: en el AGV se anticipa por kilometraje sobre ruta conocida; en el AMR se vigila por condición, porque el uso es más variable.
Baterías de litio frente a baterías de gel tradicionales
La transición tecnológica también es energética, y aquí el mantenimiento cambia de naturaleza:
Plomo-ácido / gel (AGV clásico). Requiere ciclos de carga prolongados, gestión de gasificación y, en muchos casos, salas de carga ventiladas. La disponibilidad se ve limitada por el tiempo de recarga y por el envejecimiento por ciclado profundo.
Litio (AMR y AGV moderno). Admite carga de oportunidad (recargas cortas en huecos de operación), lo que eleva la disponibilidad de flota, pero introduce el BMS (Battery Management System) como elemento crítico a vigilar: estado de salud (SoH), equilibrado de celdas y gestión térmica. Una batería de litio mal monitorizada no avisa con la degradación lenta del gel; falla de forma más abrupta.
El indicador clave a seguir es la autonomía real frente a la nominal: su caída sostenida es la señal temprana de degradación de pack y el dato que dispara la planificación de sustitución antes de que afecte a la disponibilidad de flota.
Cuadro comparativo: qué mantiene cada tecnología
AGV — Guiado fijo
AMR — Navegación autónoma
Navegación
Ruta fija predefinida (filoguiado, banda magnética, marcas ópticas, reflectores láser).
Navegación natural en tiempo real mediante LiDAR/SLAM y fusión de sensores.
Infraestructura
Requiere infraestructura física en suelo/entorno; cualquier cambio de ruta obliga a modificarla.
Sin infraestructura física: la ruta es un mapa virtual reconfigurable por software.
Sensórica clave
Sensores de seguimiento de guía y bumpers/scanners de seguridad.
LiDAR de seguridad y de localización, cámaras y odometría; calibración crítica.
Desgaste mecánico
Predecible por repetir trayectoria; desgaste de ruedas, escobillas y elementos de seguimiento de guía.
Variable por giros y reorientaciones continuas; desgaste asimétrico de ruedas motrices y reductoras.
Energía / batería
Habitualmente plomo-ácido / gel: cargas largas y salas ventiladas.
Litio con carga de oportunidad y BMS a vigilar (SoH, equilibrado, térmica).
Mantenimiento característico
Mantenimiento de rutas en suelo, sustitución de escobillas y verificación de la guía física.
Calibración de sensores ópticos de seguridad, mantenimiento del mapa virtual y actualización de software/firmware.
Conclusión operativa: mantener una flota mixta AGV+AMR no es escalar el mismo plan, sino ejecutar dos planes coordinados. Confundir guiado fijo con navegación autónoma —o gel con litio— se paga en disponibilidad de flota, el KPI que sostiene el throughput de toda la instalación.
Auditoría técnica de PLCs y buses de campo ante el Peak Season
En un almacén automatizado, el activo más crítico no siempre es el que se ve. El PLC (Programmable Logic Controller, o autómata programable) es el cerebro eléctrico de la instalación: procesa en tiempo real las señales de sensores y actuadores y gobierna el movimiento de transportadores, transelevadores y automatismos. Junto con los armarios y los buses de campo conforma el sistema de control y, a la vez, el punto ciego del mantenimiento. Auditarlo antes de una peak season como el Black Friday es lo que separa una campaña bajo control de una parada catastrófica en el peor momento del año.
Por qué el control es el punto ciego del mantenimiento
Un fallo de control rara vez avisa con un ruido o una fuga. Se manifiesta como un retardo intermitente, una variable que se desborda bajo carga máxima o una comunicación que pierde tramas solo cuando todos los nodos transmiten a la vez —es decir, justo durante el pico. Por eso una instalación puede pasar meses "sin incidencias" y colapsar el primer sábado de campaña: el defecto latente solo se expresa bajo la carga que la peak season impone.
Auditoría de armarios eléctricos
El armario es donde el control se encuentra con la potencia, y donde la carga térmica de campaña hace aflorar los defectos. La auditoría preventiva cubre:
Termografía bajo carga. Inspección termográfica de embarrados, bornes y protecciones para detectar puntos calientes por apriete deficiente u oxidación antes de que provoquen un disparo. Un punto caliente a 60% de carga será un fallo a 100%.
Verificación de aprietes. Los ciclos térmicos aflojan conexiones; el reapriete con par controlado es mantenimiento preventivo puro.
Estado de ventilación y filtros. Un armario que evacúa mal el calor degrada CPU y fuentes precisamente cuando más se le exige.
Diagnosis avanzada sobre el control: lectura de PLC y buses de campo directamente sobre el conexionado.
Integridad de las comunicaciones: Profinet y Profibus
El bus de campo es el sistema nervioso del almacén, y su salud se mide, no se supone:
Profibus. Análisis físico de la señal: niveles, reflexiones, terminaciones y calidad por nodo. Un segmento con reflexiones tolera la operación normal y falla bajo tráfico denso.
Profinet. Diagnóstico de red industrial: tiempos de ciclo, jitter, tramas descartadas, carga de los switches y estado de los puertos. El objetivo es detectar el nodo que introduce latencia antes de que esa latencia se convierta en una parada de seguridad.
Nodo 14 · Estación de cargaERROR · puerto inestable · 37 tramas descartadas
Switch S-2 · carga78% · revisar bajo tráfico pico
Lectura tipo: el Nodo 14 introduce latencia que la operación normal tolera, pero que bajo el tráfico de campaña degrada el ciclo y puede forzar una parada de seguridad. Se corrige antes del pico, no durante.
Limpieza del histórico de fallos del PLC
El buffer de diagnóstico del PLC es un activo infrautilizado. Antes de campaña conviene analizar y depurar el histórico de fallos: clasificar las alarmas recurrentes, distinguir el ruido de los avisos significativos y resolver las causas raíz de los warnings que el operador ha aprendido a ignorar. Un histórico saturado de alarmas crónicas hace que el aviso realmente crítico pase desapercibido durante el pico.
Prueba de redundancias antes del pico
Las redundancias —CPU redundante, fuentes de alimentación dobles, anillos de red— solo aportan valor si se verifican. La auditoría pre-peak incluye provocar el conmutado de forma controlada para confirmar que la conmutación ocurre sin pérdida de proceso. Una redundancia que nunca se ha probado es una suposición, no una protección.
Calendario recomendado
La auditoría de control debe ejecutarse con margen suficiente —idealmente entre seis y ocho semanas antes del pico— para que haya tiempo de corregir los hallazgos sin trabajar contrarreloj. Auditar la víspera solo confirma el problema; auditar con antelación permite resolverlo dentro de una ventana planificada.
Conclusión operativa: el correctivo sobre el control durante la campaña siempre llega tarde y caro. La auditoría preventiva de PLCs y buses de campo convierte el cerebro del almacén de punto ciego en variable bajo control, y mueve el riesgo fuera del momento en que la instalación menos puede permitirse parar.
Indicadores críticos en el mantenimiento de almacenes automatizados
El mantenimiento preventivo se aprueba en dirección general cuando deja de presentarse como un gasto técnico y empieza a expresarse como rentabilidad. Para eso hay que recorrer una cadena de indicadores: del MTTR y el MTBF a la disponibilidad, de la disponibilidad al OEE, y del OEE al euro.
Las definiciones, sin ambigüedad
MTBF (Mean Time Between Failures): tiempo medio entre fallos de un activo. Mide fiabilidad. Sube cuando el preventivo y el predictivo evitan que el fallo ocurra.
MTTR (Mean Time To Repair): tiempo medio para devolver el activo a producción tras el fallo. Mide capacidad de respuesta. Baja con repuestos críticos en stock, procedimientos documentados y un partner cercano.
Disponibilidad: proporción del tiempo en que la instalación está operativa. Es función directa de los dos anteriores.
OEE (Overall Equipment Effectiveness): efectividad global, producto de tres factores: Disponibilidad × Rendimiento × Calidad.
Veámoslo con un ejemplo ilustrativo. Supongamos un sistema con un MTBF de 200 h y un MTTR de 8 h:
Disponibilidad = 200 / (200 + 8) = 96,2 %
Ahora apliquemos dos mejoras típicas de un buen programa de mantenimiento. Primero, reducir el MTTR de 8 h a 4 h (repuestos en stock + partner local que acorta el tiempo de respuesta):
Disponibilidad = 200 / (200 + 4) = 98,0 %
Y, en paralelo, elevar el MTBF de 200 h a 300 h mediante sustitución por condición y predictivo:
Disponibilidad = 300 / (300 + 4) = 98,7 %
Pasar de 96,2% a 98,7% parece poco. No lo es.
Del dato al euro: la disponibilidad se traduce en horas de producción y en cuenta de resultados.
Del punto de disponibilidad al euro
Sobre una operación que funciona 6.000 horas al año, cada punto porcentual de disponibilidad equivale a 60 horas de capacidad. La mejora del ejemplo —de 96,2% a 98,7%, es decir 2,5 puntos— recupera 150 horas de producción al año que antes se perdían en paradas.
Si una hora de parada en esa instalación tiene un coste plenamente cargado de, supongamos, 3.000 €/h (producción perdida + penalización de SLA + sobrecoste de recuperación), el cálculo para dirección es directo:
Y como el OEE es multiplicativo, esa mejora de disponibilidad arrastra todo el indicador: si Rendimiento y Calidad se mantienen, el OEE sube en la misma proporción que la disponibilidad, sin tocar ni la velocidad del sistema ni la tasa de errores.
El ROI del programa preventivo
Con el downtime evitado cuantificado, justificar la inversión es una resta:
ROI = (Downtime evitado − Coste del programa) / Coste del programa
Mientras el coste anual del programa preventivo/predictivo se mantenga muy por debajo de las pérdidas que evita —y en instalaciones críticas la diferencia suele ser de un orden de magnitud— la conversación con dirección deja de ser sobre el coste del mantenimiento y pasa a ser sobre el coste de no hacerlo.
Conclusión operativa: MTBF y MTTR no son métricas de taller; son las dos palancas que mueven la disponibilidad, y a través del OEE, la cuenta de resultados. El trabajo del partner de mantenimiento es subir una y bajar la otra, y demostrarlo con datos cada trimestre.
El Service Partner local en contratos de mantenimiento de grandes integradores
Los grandes integradores internacionales de intralogística diseñan e implantan sistemas excelentes. Pero el ciclo de vida de una instalación se mide en años de operación diaria, y ahí la distancia geográfica entre la ingeniería del integrador y el activo en planta se convierte en un coste operativo real. El Service Partner local existe para cerrar esa brecha.
El coste de la distancia
Cuando el soporte técnico de referencia está a cientos o miles de kilómetros, cada incidencia que excede la capacidad del equipo de planta arrastra una penalización doble: el tiempo de viaje del especialista y la logística de repuestos. Ambos inflan directamente el MTTR, y el MTTR erosiona la disponibilidad y el OEE.
La diferencia entre un ingeniero de campo a menos de dos horas de la planta y uno que debe desplazarse desde otro país no es de comodidad: es de horas —a veces días— de instalación parada esperando manos cualificadas sobre el activo. En una operación crítica, esa espera es la parte más cara de toda la avería.
Soporte a pie de instalación: la proximidad reduce el tiempo de respuesta y, con él, el MTTR.
Por qué la proximidad es una métrica, no un eslogan
La proximidad se traduce en un parámetro medible: el tiempo de respuesta on-site. Reducirlo es la palanca más directa sobre el MTTR que un contrato de mantenimiento puede ofrecer. Un brazo técnico nativo en Cataluña permite atender en horas lo que de otro modo entraría en la cola de planificación internacional del integrador, sujeta a disponibilidad de agenda y a desplazamientos transfronterizos.
Para el integrador, además, externalizar la presencia local en un partner especializado evita el coste fijo de montar y mantener estructura propia en cada región donde tiene instalaciones —un coste que rara vez se justifica para un parque de máquinas disperso.
El modelo de colaboración: Nivel 1 y Nivel 2
El Service Partner local no compite con el integrador; lo complementa con una división de responsabilidades clara:
Nivel 1. Atención de primera línea sobre el terreno: inspección, mantenimiento preventivo, sustitución de componentes y resolución de las incidencias más frecuentes sin necesidad de escalar.
Nivel 2. Diagnóstico técnico avanzado de mecánica, electrónica y control, resolviendo en planta una proporción elevada de incidencias y reservando para el fabricante únicamente lo que exige ingeniería de producto o software propietario.
El integrador conserva la relación comercial, la ingeniería y la propiedad del sistema; el partner aporta las manos, los ojos y el criterio técnico locales. El cliente final gana un único interlocutor cercano que responde rápido.
La documentación técnica como acelerador de decisiones
La proximidad resuelve el tiempo de llegada; la documentación resuelve el tiempo de decisión. Un ingeniero de campo que entrega un informe claro —hallazgos, criticidad, evidencias y recomendación priorizada— permite que el responsable del integrador o el cliente final decida con criterio técnico y sin segundas visitas. La buena documentación convierte una incidencia en una decisión tomada en una sola iteración.
Conclusión operativa: para una multinacional de intralogística, un Service Partner local especializado no es un proveedor más, sino la extensión que protege el MTTR, la disponibilidad y la relación con el cliente final en el mercado donde tiene los activos. Cercanía, especialización y documentación: las tres reducen el tiempo que separa un fallo de su solución.
Retrofitting: alargar la vida útil de un almacén automatizado sin detener la operación
Una instalación intralogística no se queda obsoleta de golpe: lo hace por partes. El control envejece antes que la mecánica, los repuestos dejan de fabricarse y el software pierde soporte mientras la estructura sigue siendo perfectamente válida. El retrofitting —modernización selectiva de los componentes críticos sin sustituir toda la instalación— es la vía para extender la vida útil del activo protegiendo la inversión y, sobre todo, la continuidad operativa.
Por qué una instalación envejece por capas
La vida útil de la mecánica de un almacén automatizado (estructura, raíles, transportadores) se mide en una o dos décadas. La de su electrónica de control y su software es mucho más corta: un PLC o una variadora pueden quedar fuera de soporte del fabricante en pocos años, y con ellos desaparecen los repuestos y las actualizaciones. El resultado es una instalación mecánicamente sana pero en riesgo de obsolescencia en su sistema nervioso, donde un único componente sin recambio puede dejar parada toda la línea.
Retrofit de control: integrar hardware modular de última generación sobre la instalación existente.
Qué se moderniza (y qué se conserva)
El retrofitting bien planteado interviene solo donde aporta valor y deja intacto lo que sigue siendo fiable:
Control y automatización. Sustitución de PLCs y buses de campo obsoletos por arquitecturas con soporte, recambio y capacidad de diagnóstico.
Accionamientos y electrónica de potencia. Variadores, motores y protecciones con mejor eficiencia y disponibilidad de repuestos.
Sensórica y seguridad. Actualización de elementos de seguridad a la normativa vigente.
Software y supervisión. SCADA/WMS y capa de datos para habilitar el mantenimiento predictivo.
Se conserva la estructura, los raíles y la mecánica que aún están dentro de tolerancia, evitando una inversión de reposición total.
Cómo hacerlo sin detener la operación
La clave del retrofit es ejecutarlo por fases y dentro de ventanas planificadas, no como una parada total. Se segmenta la instalación, se interviene por zonas durante las ventanas de menor actividad y se aprovechan las redundancias para mantener el flujo. Cada fase se valida antes de pasar a la siguiente, de modo que la operación nunca pierde más capacidad de la que el plan ha previsto.
Una auditoría previa documentada es imprescindible: identifica los componentes en riesgo de obsolescencia, prioriza por criticidad y define el orden de las fases. Sin ese diagnóstico, el retrofit se convierte en una reforma improvisada con riesgo de parada.
El caso económico del retrofit
Frente a la sustitución completa, el retrofitting concentra la inversión en los componentes que de verdad la necesitan, y lo hace antes de que el fallo llegue. Los indicadores que justifican la decisión ante dirección son claros: reducción del riesgo de parada por obsolescencia (componentes sin recambio), mejora del MTBF al introducir electrónica nueva, reducción del MTTR al recuperar disponibilidad de repuestos, y extensión de la vida útil del activo sin el desembolso de una instalación nueva ni el lucro cesante de una parada prolongada.
Conclusión operativa: el retrofitting no es reformar por reformar, sino gestionar la obsolescencia antes de que se convierta en parada. Modernizar el control y la electrónica críticos, por fases y documentado, alarga la vida útil de la instalación protegiendo a la vez la inversión y la continuidad operativa.